大模型(LLMs)在各种任务上的出色表现已经是有目共睹。
根据我个人使用GPT-4的体验来说,无论是对指令的理解还是生成的质量,其表现都堪称完美。
不过,它们仍然面临一些局限性。最影响我本人使用体验的就是LLMs捉襟见肘的上下文长度(Context length)。
虽然GPT-4的context length有8192 tokens,约5700个词。但在诸如长文档(如论文)摘要,超多轮对话,代码debug等任务里,还是经常出现瓶颈。
这一问题对于常见的开源LLMs尤为明显。例如,LLaMA和OPT等模型的context size均为2048,仅为GPT-4的四分之一。
所以在部署开源模型时,可以预见用户对于context length的限制感受将更加明显。
针对fixed context length的新技术
针对context length的限制,有很多新技术致力于拉长模型的上下文窗口。
例如,Longformer的linear attention;CoLT5的Light attention和Light MLP。
大部分现存的方法都是通过对模型架构的改进,来实现处理更长上下文的目的。不过由于现有的开源LLMs还没有应用此类技术,所以远水解不了近渴。
本文尝试一种即插即用,和架构无关的思路,通过压缩prompt来更有效率地使用模型的context。
压缩prompt,更有效率地使用模型的context
为什么要压缩prompt?
首先考虑经典的论文问答任务。prompt一般会包含问题和背景文章。而我们可以想象,对于LLMs来说,背景文章中包含了许多的冗余内容:比如对论文背景的介绍,对论文相关工作的介绍等。
这些内容往往是为了照顾不了解背景的读者而添加,不过由于LLMs在训练的过程中很大概率已经见到过类似内容的文本,所以这些内容并没有带来新的信息。
举个例子:
Prompt: Why do we need LLMs? Answer based on the following passage:
—–
Large language models (LLMs) have demonstrated remarkable power and impressive generalisation abilities across a wide range of natural language processing tasks, as well as real-life applications. However, a major limitation of LLMs is their fixed context length. As LLMs have no memory outside their context window, it poses a significant challenge when tackling tasks that involve processing long documents or engaging in extended conversations.
GPT: We need LLMs because they have demonstrated impressive abilities in natural language processing tasks and real-life applications.
而如果我们删去相关的内容再来一次:
Prompt: Why do we need LLMs? answer based on the following passage:
—–
Large language models (LLMs) have demonstrated {..deleted}. However, a major limitation of LLMs is their fixed context length. As LLMs have no memory outside their context window, it poses a significant challenge {.deleted}.
GPT: LLMs are needed because they have demonstrated impressive capabilities in various natural language processing (NLP) tasks.
我们发现,即使相关内容被删掉,GPT仍然给出了几乎相同的答案。
原因很简单,删去的内容GPT已经学习过,所以并没有新知识/内容的介入。即使删去也不会影响GPT给出正确答案。
根据这一发现,我们可以通过删去没有新内容(less informative)的方式来压缩prompt,从而在有限的context中放入尽可能多的内容。
Prompt压缩
Prompt压缩的首要问题在于,确定需要压缩的内容。换句话说,判断哪些文本并不能为LLMs带来新的信息。
我们在这里采用self-information来对这一点进行衡量。
Self-information也称为surprisal。在信息论中,self-information被用于衡量一个event在一个特定的概率分布中所蕴含的信息。在LLMs的背景下,这里的概率分布可以视为language model,而event可以视作一段文本。
也就是说,self-information衡量了一段文本相对与一个language model所蕴含的信息。
Self-information的计算格外简单,将log probability取负即可得到self-information �(�).
�(�)=−log�(�)
这里的P可以是小号的LLMs,不需要是大模型本体。例如1.3b的OPT和OpenAI-Curie(6.3b).
Prompt压缩的整体过程十分简单。
- 首先计算文本中每个短语的self-informaiton。
- 再根据想要的压缩比设置百分位数,得到阈值。
- 最后删去低于阈值的短语。
除了以短语为单位,我们当然也可以采用词,或句子为基础单位来计算self-information和做内容删减。

上图展示了在压缩比例设为0.5时,Selective Context是如何精简论文introduction的。背景的颜色深浅表示其self-information的大小。
实验
为了测试压缩prompt到底行不行得通,我们考虑三个需要用到超长context的场景:
- 超长对话
由于开源大模型的context窗口较小,所以上线后的常见问题之一就是,用户经常发现自己前几轮的内容随着对话变长被忘掉了。
所以这里我们测试一下prompt压缩能否帮助这一场景。
- 长文档(e.g., 论文,法律文档)
处理长文本是很常见的用户需求,比如摘要论文,法律文档问答等。这里我们测试一下prompt压缩能否帮助处理长文档。
- 长新闻
新闻往往没有那么长,不过在处理金融,舆情等内容时,常常会希望能同时处理多条新闻。这里我们也会测试prompt压缩能否帮助这一场景。
为此我们使用了以下三个数据源作为测试数据:
- http://ShareGPT.com:收集用户与GPT对话记录的网站
- Arxiv
- BBC News
针对以上三种场景,我们设置了一些具体的任务:
- http://ShareGPT.com:对话
我们使用http://ShareGPT.com上的原始对话记录作为标准答案,将其与应用prompt压缩后的性能做比较。
- Arxiv
- BBC
我们用摘要(Summarisation)和问答(QA)来测试prompt压缩在长文档和长新闻上带来的收益。
我们将未压缩时的答案作为标准答案,将其与应用prompt压缩方法后的性能做比较。
结论
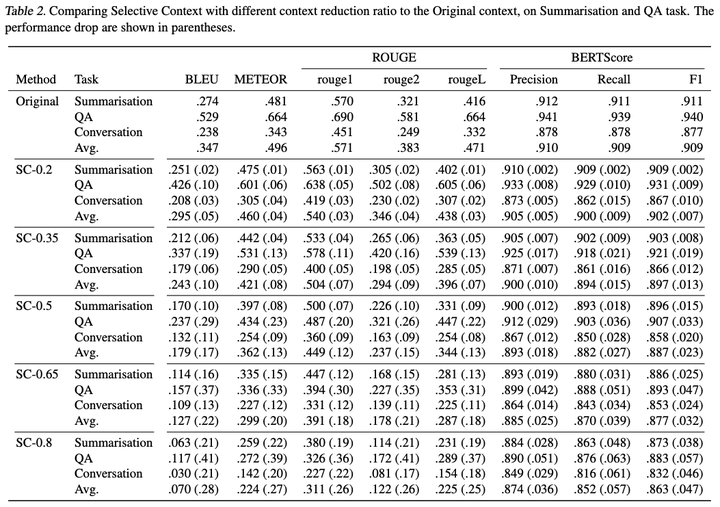
在不同任务上的结果如上表所示。
- 在压缩比例设为0.2时,模型的生成性能只有很微小的下降。ROUGE下降了约0.03,而BERTScore下降了约0.007.
- 在压缩比例设为0.35时:ROUGE下降了约0.07,而BERTScore下降了约0.013. 依然是较小的下降。
- 在压缩比例设为0.5时:ROUGE下降了约0.12,BERTScore下降了0.23. 下降较为严重。不过在摘要和对话任务上,模型依然能获得很不错的性能。
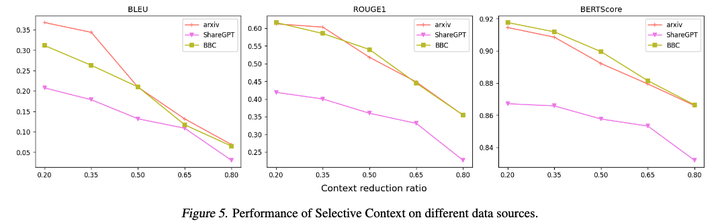
我们将三个数据源的结果分开来看。能够发现,prompt压缩在长文档和长新闻上,都是可以较好处理的。而在对话数据上表现略逊一筹,不过在压缩率高于0.5时,依然和baseline保持较小的差距。
综上,“虽然没有免费的午餐”,不过对prompt做压缩依然能在不牺牲很多性能的情况下,大幅度提高有限context能够处理的信息量,可以算作是“性价比很高的午餐了” 。
参考
对Prompt压缩个人认为是很有价值的。
一是,其即插即用的特性,在部署模型的时候可以成本很低地提高用户的体验。而且整个计算过程不需要大模型本体介入,计算开销也很低。
二是,LLMs对输入有那么强的鲁棒性,确实是很值得研究的课题。
本文只能算是初期的一些工作,非常需要大家的反馈和建议。如有任何想法都欢迎私信联系,大家一起改进完善实验和改进方法。
在线体验prompt压缩,可以访问Huggingface Hub上的demo:

论文:
代码:
相关文章
