
OpenAI最新版本的大模型GPT-4.1正式上线。
目前,GPT4.1只在API上供开发者使用,未引入聊天机器人ChatGPT。它共有三个版本,标准版的GPT-4.1, 和两个小一点的版本GPT-4.1 mini、GPT-4.1 nano。
在当地时间4月14日发布的直播上,OpenAI表示,GPT-4.1拥有比GPT-4o更大的上下文窗口,在“每一个维度”都比4o更好,尤其在写代码和遵循指示方面有了长足提升。
其中,GPT-4.1的上下文窗口高达100万token,相当于能一次性输入75万个单词(比《战争与和平》还要长)。这远高于4o的12.8万token限制。OpenAI表示,“我们对其进行了训练,使其在定位相关文本和忽略不同语境中的干扰时,比GPT-4o更可靠。”

虽然OpenAI的新模型总是被寄予厚望,但随后的评测结果显示,GPT-4.1只是对GPT-4o的一版小升级,它在一众指标中都落后于谷歌旗下的Gemini 2.5,并且成本是Deepseek V3的8倍。
文/承天蒙
/01/
上线计划一改再改
不久前,OpenAI刚宣布,已经发布了两年的GPT-4将于4月30日起从ChatGPT中退役,被GPT-4o完全取代。GPT-4o正式成为了ChatGPT的默认模型。
GPT-4于2023年3月推出,用于ChatGPT和微软Copilot聊天机器人。它是OpenAI推出的第一个多模态大模型,可以同时理解图像和文本,具有划时代的重要意义。当时,GPT-4的数据规模还很大,训练成本超过一亿美元。在GPT-4这一先行者的引领下,后续一众多模态大模型也如雨后春笋般冒了出来,开启了AI大模型百花齐放的新时代。
GPT-4o是GPT-4的后继版,在写作、写代码、STEM等方面优于GPT-4。不久前,GPT-4o新上线的图像生成功能大受欢迎,它能提供包括吉卜力工作室风格在内的20余种图像风格。最近的升级也进一步提高了GPT-4o在遵循指令、解决问题和对话流程上的表现。现在的ChatGPT已经能记住用户和它说过的每一句话,并参考过去的聊天记录,提供更加个性化的回复。
此次GPT-4.1全面超越了GPT-4o,与此同时,它还全面超越了OpenAI两个月前刚刚发布的GPT-4.5。是的,小数点后面的数字已经不重要了,目前的现状是,OpenAI在GPT-4.5之后推出了性能更优异的GPT-4.1。而更重要的大更新版本GPT-5,宣布难产。

一周前的4月4日,OpenAI的CEO山姆·奥特曼宣布公司旗下发布大模型的计划有变,将会推出其推理模型o3和一个o4 mini的完整版,GPT-5的发布时间将会推迟。原定5月发布,现在应该会在“几个月内”发布。奥特曼表示,推迟的部分原因是“顺利整合一切比我们想象的更难”。
推出了更先进的小版本更新4.1后,OpenAI也将从7月14日起,下线API中的GPT-4.5,因为“GPT-4.1已经证明可以用更低价格、更少延迟,在众多关键指标上提供类似或更佳的表现。”
GPT大模型从未停止研发和进化。但是在现在行业竞争加剧、众敌环伺的情况下,OpenAI无疑更新地更频繁了,推出的大模型版本也更多。能看出来,OpenAI始终希望让自己与竞争对手保持一定的领先地位,但至少4.1没有做到这一点。GPT-4.1被评价为“首次在谷歌之后推出了一个远远落后于谷歌的版本”。
/02/
强敌环伺
当下,无疑是全世界各大厂商开足马力逐鹿大模型的时代。谷歌近期发布了Gemini 2.5 Pro,同样拥有100万token的上下文窗口,并且在行业评分中名列前茅。Anthropic旗下Cloude 3.7 Sonnet和中国的Deepseek V3升级版同样也是强劲的竞争对手,在很多指标上都超越了GPT-4.1。
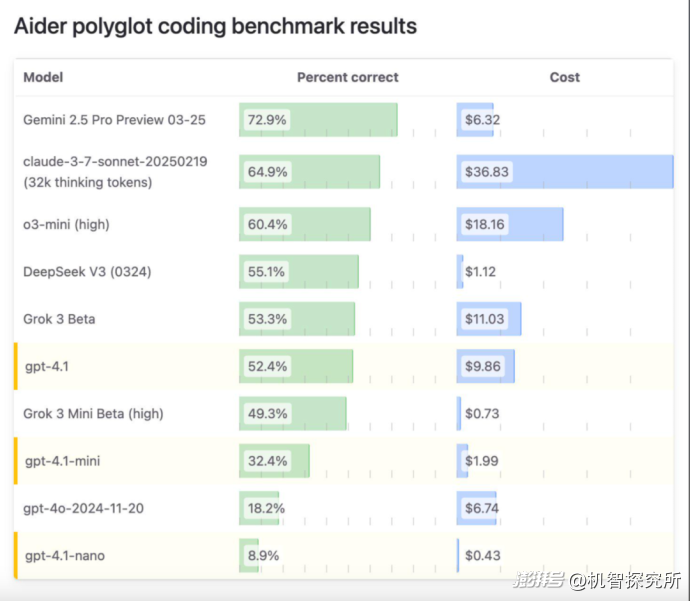
▲知名大模型的代码的能力和成本比较,GPT4.1在里面排名第6,其中第三名的o3 mini(high)是OpenAI的推理模型
根据OpenAI的内部测试,GPT-4.1 一次可生成token数为32768,多于GPT-4o的16384,在 SWE-bench Verified上的得分介于52%和54.6%之间。但这些数字略低于谷歌Gemini 2.5 Pro的63.8%和Anthropic旗下Claude 3.7 Sonnet的62.3%。
OpenAI也承认,GPT-4.1需要处理的token越多,就越容易出错。在该公司自己的一项测试中,GPT-4.1的准确率在8000个token时是84%左右,100万个token时便下降到50%。OpenAI还表示,GPT-4.1比GPT-4o更 “直白”,有时需要更具体、更明确的提示。
更多实测证明,GPT-4.1的编码能力极强,但总体看来很多情况下打不过Gemini 2.5 pro和Claude 3.7 Sonnet,并且它的价格是Deepseek V3的8倍。在最新Livebench基准评估中,也同样印证了GPT-4.1推理、编码、数学实力比Gemini 2.5差。

▲各家厂商每一百万token成本比较
还有一个需要关注的问题是,分数差这么多,不单纯是因为Gemini 2.5 pro比GPT-4.1更高效。谷歌是在自己的ASIC(TPU)上运行的模型,ASIC(TPU)是比GPU专业的芯片,这让谷歌运行模型的成本比竞争对手低得多,这是谷歌在AI领域软硬件全面发展的实力。
/03/
大模型往何处去
执行复杂的软件工程任务,一直是AI大模型训练的目标。OpenAI首席财务官Sarah Friar此前在一个技术峰会上曾表示,OpenAI的宏伟目标是创建一个“软件工程师助手”,公司认为,其未来的模型将能够对整个应用app进行端到端编程,处理包括质量检测、bug测试和文档写作等方面的工作。

▲OpenAI旗下不同GPT模型的跑分比较
GPT 4.1就是朝这个方向迈出的一步。
OpenAI表示,完整的GPT-4.1模型优于GPT-4o和GPT-4o mini模型。GPT-4.1 mini和nano更高效、更快速,但牺牲了一些准确性,OpenAI还表示,GPT-4.1 nano是其有史以来最快速、最便宜的模型。根据网络评测,GPT-4.1 nano的成本不到Deepseek V3的一半。
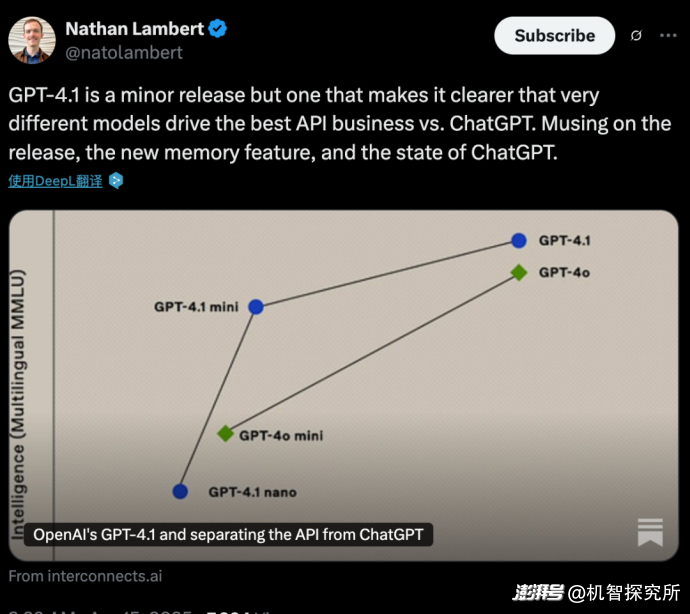
GPT-4.1发布后,AI研究机构Ai2的工程师Nathan Lambert表示,虽然GPT-4.1是一个小版本的更新,但这让人们更清楚地认识到,推动 API 业务和 ChatGPT 最佳体验的是两个截然不同的模型。
在通用大模型的基础上,区分API业务和ChatGPT,推出多版适合不同场景、不同版本、各有长处的模型,可以起到降低成本、提高效率的作用,这同样成为了OpenAI未来大模型的发展方向。照此看来,GPT-4.1也许是未来OpenAI发展不同大模型产品线的重要一步。
阅读原文
文章来源于互联网/AI生成
相关文章
