
日前,Meta(原Facebook)推出了Llama 4的3个版本,Llama 4 Scout、Llama 4 Maverick和Llama 4 Behemoth。在大模型竞技场(LMSYS Chatbot Arena)的盲测跑分中,Llama 4 Maverick 的总排名第二,成为第四个突破 1400分的大模型。不仅在开放模型中排名第一;在困难提示词、编程、数学、创意写作等任务中也均排名第一。
但怀疑随之而来,因为众多网友下载实测后,发现Llama 4的表现很差,根本不像是在竞技场排名第一的水平。此外,在竞技场之外的第三方评测中,Llama 4排名都是垫底,表现远不如Gemini和Deepseek。更有匿名员工在论坛爆料称Llama 4的研发有不端行为,自己已经辞职,并要求不在Llama 4的技术报告上署名。

文/承天蒙
/01/
广泛批评和质疑
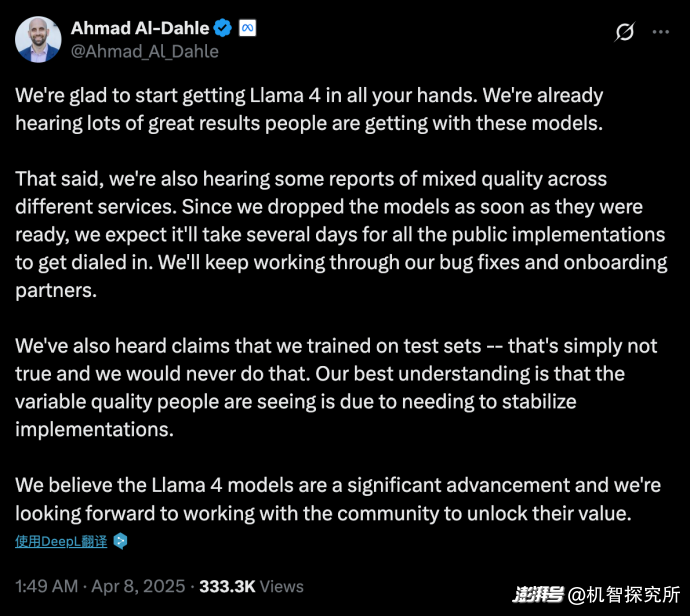
不久,大模型竞技场母公司LMSYS发布官方声明,称Meta交给竞技场的Llama 4是针对评测指标优化过的特供版,和网友们下载的正常版本不一样。LMSYS批评了Meta这种打擦边球的行为,表示会用Llama 4的正常版重新评测。
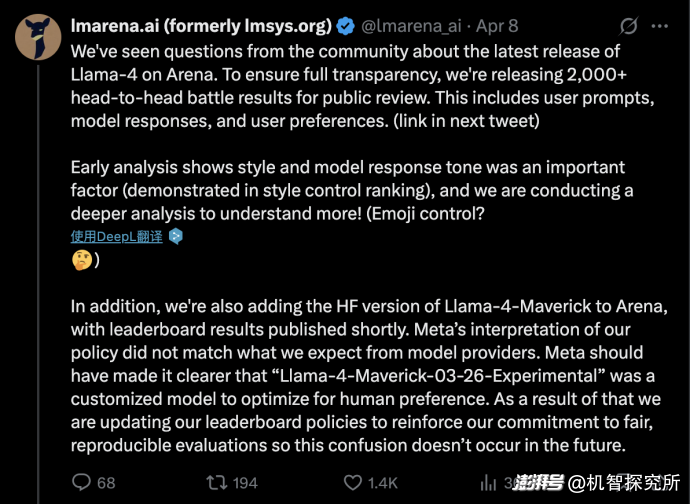
面对铺天盖地的批评和指责,Meta的副总裁兼GenAI负责人Ahmad Al-Dahle在X上发表声明,否认了在测试集上训练的指控,并将质量不稳定的问题归因为bug。
那么Llama 4究竟是怎样的技术路线,它的真实水平又如何呢?
/02/
被公司给予厚望
多模态大语言模型(Multimodal Large Language Models,简称MLLM),结合了大语言模型(LLM)的自然语言处理能力,和对其他模态(如视觉、音频等)数据的理解与生成能力。它能够处理和理解来自文本、图像、声音等不同模态的信息,并将这些信息整合,以完成复杂的任务。可以说,多模态大模型是普通大语言模型的进化态,也是未来前往通用人工智能的必经之路。谷歌Gemini,OpenAI的GPT-4都是多模态大语言模型。
在大模型的军备竞赛中,Meta作为依靠Facebook、Instagram等社交媒体赚得盆满钵满的互联网科技公司,在AI技术上不甘落为人后。但现实却很骨感。Llama 3.3刚刚发布一个月,Deepseek R1便横空出世,在预算少的多的情况下取得了更好的成绩。Llama 3.3甫一面世就直接过时,这让Meta受到了巨大的震撼,科技媒体报道称,Meta管理层对自己进行了反思。
由于资本市场的施压,Meta计划今年在AI领域投资650亿美元,势必要做出一番成绩。对其自家的多模态大模型Llama 4,Meta更是给予厚望。
在其官方新闻稿中,Meta表示,Llama 4 Scout和Llama 4 Maverick是其“迄今为止最先进的模型”,也是“同类产品中多模态性能最好的”。Llama 4 Behemoth目前还正在训练,但CEO马克·扎克伯格已经表示,Behemoth是“全世界表现最好的基础预训练模型。”
/03/
亮点:1000万token的上下文窗口
Llama 4的三个版本,均采用了“混合专家模型”(Mixture of Experts,简称MoE)架构和一种新的固定超参数(hyperparameters)的训练方法。其特别之处在于设置了高达1000万个token的上下文窗口,这是AI大模型与用户一次输入/输出能处理的信息量,相当于AI的工作内存。Meta将之评价为“行业领军”。
混合专家模型是一种机器学习方法,它将任务拆分为若干子任务,并将每个子任务分配给专门解决该类问题的神经网络子系统。每个“专家”负责解决问题的一部分,最终将各自的结果合并成一个整体输出。DeepSeek-V3就是一个MoE模型,因此MoE被普遍认为能在降低资源消耗的同时提升输出质量。
据Meta介绍,Llama 4 Scout拥有1090亿个参数,每次调用会激活16个专家模型中的170亿个参数。Meta称,该模型可以部署在一块Nvidia H100 GPU上——不过这需要进行大幅量化处理,即对模型参数进行压缩和量化,从而降低模型的存储和计算复杂度。而且即使如此,其高达1000万个token的上下文窗口也无法充分利用。
Llama 4 Maverick体量更大,拥有128个专家模型,总参数量达4020亿,但与Scout一样,每次调用仍只激活170亿个参数。
Scout和Maverick都是基于Llama 4 Behemoth。Meta表示,Behemoth拥有2880亿个活跃参数、16个专家模型,以及接近两万亿的总参数规模。
/04/
跟随者
Meta称,Llama 4 Scout“在广泛报道的基准测试中 ”击败了谷歌的Gemma 3和Gemini 2.0 Flash-Lite模型,以及开源的Mistral 3.1,同时仍然 “适合单个Nvidia H100 GPU”。并称其Maverick 模型在编码和推理任务中的结果可与 DeepSeek-V3 相媲美,使用的“活动参数不到其一半”。现在看来,这究竟是事实说话,还是自吹自擂,需要靠实践出真知了。
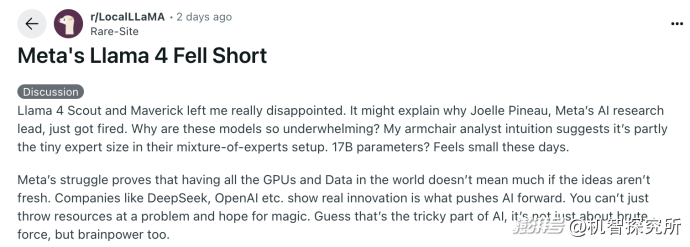
社交网络上,试用了Llama 4的网友对其表示失望,网友评价称:“Meta的挣扎证明,如果你的idea不新鲜,即使拥有世界上全部的GPU和数据也没什么意义。Deepseek和OpenAI这样的公司才表现出了推动AI前进的真正创新。”
作为大模型和AI研发的跟随者,Meta虽然有钱,也渴望做出一番成绩,但从Llama 4目前的表现来看,Meta在大模型领域还有很长一段路要走。
阅读原文
文章来源于互联网/AI生成
相关文章
