作者:费斌杰 北京市青联委员 熵简科技CEO
ChatGPT之父Ilya Sutskever官宣从OpenAI离职后,第一时间点赞了一篇AI论文,引起了广泛关注。
这篇论文的标题是《The Platonic Representation Hypothesis》(柏拉图表征假说),由MIT团队于上周发表。
周末我花时间仔细读完了这篇论文,有着难以言喻的震撼。作为Gen AI的开创者,Ilya精选的论文果然不同凡响。
这篇论文对未来AI发展路径和方向有着指导意义。无论你是科技投资人、AI从业者、还是对AI感兴趣的朋友,都值得一读。
我给大家解读一下这篇论文的精华内容,报告链接放在文末,欢迎感兴趣的朋友去看原文。
相信看完这篇文章,你对深度学习模型的未来,会有一个全新的哲学认知。
(1)柏拉图的洞穴寓言
一切得从柏拉图的洞穴寓言说起。
洞穴寓言是柏拉图在其著作《理想国》中提出的一个思想模型,探讨了何为“现实”。
在洞穴寓言中,有一群囚犯,他们一生都被锁链拴在洞穴中,对于洞穴外的世界一无所知。
他们一直面对着一面墙壁,只能看到身后各种事物在墙壁上的影子。

长此以往,这些影子便成为了他们眼中的“现实”,但这却不是真实世界的准确表达。
在洞穴寓言中,“影子”代表我们通过各种感官感知到的现实片段,无论是通过眼睛看到的图像、耳朵听到的声音、双手触摸的形状,都只是“现实”的种种投影罢了。
柏拉图的老师苏格拉底曾说过,哲学家就像是从洞穴中获释的囚犯,他们走出洞穴来到阳光下,逐渐明白墙上的影子并不是“现实”,而是“现实”的投影。
哲学家的目标是通过逻辑、数学、自然科学等手段,去理解和感知更高层次的“现实”,去格物致知,探索“道”。
现在,这个宏伟的目标从哲学家传递到了AI科学家的手中。
(2)什么是柏拉图表征假说?
理解了柏拉图洞穴寓言后,柏拉图表征假说就比较容易理解了。
柏拉图表征假说(Platonic Representation Hypothesis)指的是,不同的AI模型正在趋向于一个统一的现实表征。
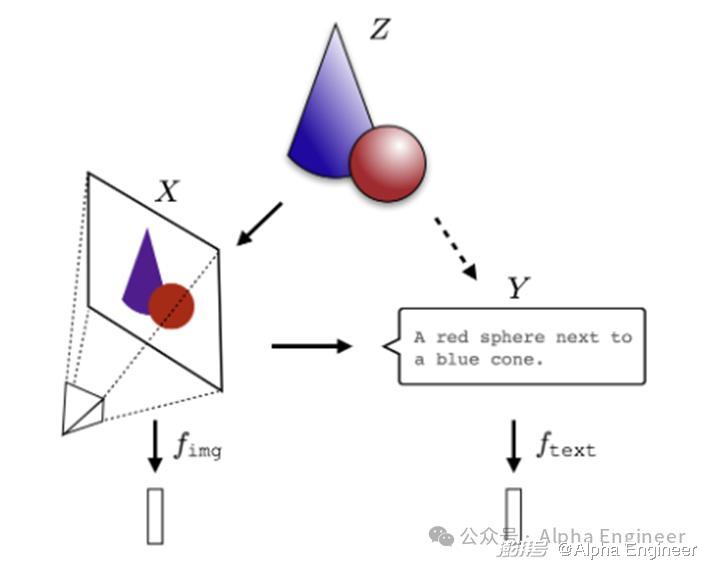
这么说可能有点抽象,我来具体解释下。
如上图所示,假设我们把现实Z具象成一个圆锥+一个圆球。那么X是现实Z的图片模态的投影,而Y是现实Z的文本模态的投影。
这时我们训练两个AI模型,一个是CV模型fimg,一个是文本模型ftext,它们各自学到了对于X和Y的表征方式。
但是随着模型参数规模、训练数据的扩大,这两个模型最终会学到X、Y这两个投影背后,现实Z的表征方式。
你可以理解为,当一个AI模型变得足够聪明时,它就不再是那个被铁链拴住的囚犯,而是成为了一名走出洞穴的哲学家。
它看到的不再是墙壁上的投影,而是逐渐理解了事物的本来面貌,感知到了更高维度的现实。
这就是柏拉图表征假说的含义。现在再看一下作者的定义,就容易理解了。

柏拉图表征假说有一个非常重要的推论,即不同模态、不同算法架构的AI模型都会汇聚到同一个终点目标,那就是形成对于高维现实的准确表征。
具体而言,这种对现实的表征可以理解为一个概率模型,它是现实事件的联合分布。
这些离散事件采样自未知分布,并且能够通过多种方式被观察感知,无论是一张图片、一段声音、一段文字,还是质量、力、力矩等等。

(3)验证柏拉图表征假说的有效性
既然这是一个假说,我们自然得寻找方法来验证其有效性。
幸运的是科学家有趁手的数学工具来进行定量分析。
Phillip将“表征对齐”(Representation Alignment)定义为两个表征的kernel上的相似性度量。

在此基础上,我们需要用到一项叫做模型拼接(Model Stitching)的技术来评估两种表征之间的相似度。

模型拼接的原理比较直观:将两个模型的中间表示层通过一个拼接层(Stitching Layer)连接起来,形成一个新的“缝合”模型。
如果这个“缝合”模型的性能良好,那么表明两个原始模型在该层的表示是兼容的,即使它们此前可能是基于完全不同的数据集进行训练的。
(4)实验结果:强者往往相似,弱者各有各的弱法
通过“模型拼接”技术,以及“表征对齐”的评估手段,我们便可以验证柏拉图假说是否真的存在。
Phillip选取了78个CV模型进行表征相似度分析,这些模型在训练数据集、任务目标、算法架构上各不相同。
实验结果非常有趣,如下图所示,我来给大家解读一下这张图。
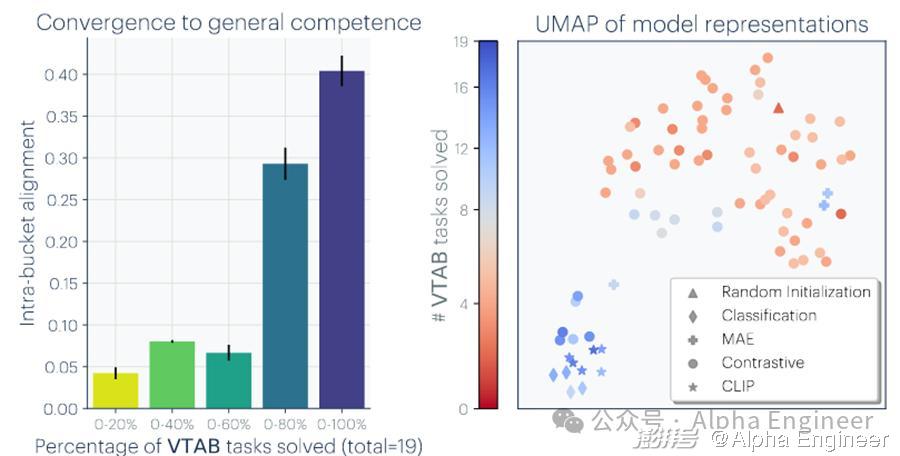
首先看左边的柱状图,横轴是模型通过VTAB任务的比例,这个比例越高说明模型性能越强。这里Phillip将78个CV模型按性能强弱分为5个bucket,越往右越强。
纵轴是每个bucket中所有模型间的表征相似度,柱子越高说明表征相似度越高。
不难看出,模型的性能越强,它们之间的表征相似度就越高。反之,模型的性能越差,它们之间的表征相似度就越低。
右边的散点图把这个结论更加明确的呈现了出来。每个点都代表一个CV模型,颜色越红说明模型越弱,颜色越蓝说明模型越强。
可以看到,强大的模型(蓝色的点)聚集在了一块儿,说明它们之间有着较高的表征相似度,而弱小的模型(红色的点)却比较分散,说明它们之间表征相似度较低。
列夫·托尔斯泰在《安娜·卡列尼娜》中曾写道:幸福的人都是相似的,不幸的人各有各的不幸。
Phillip则调皮的模仿托尔斯泰的口吻说道:强大的模型往往都是相似的,弱小的模型各有各的弱法。

(5)AI模型表征收敛背后的三大原因
通过实验结果,我们发现柏拉图表征假说确实存在。
那么AI模型为什么会呈现出如此明显的表征收敛性质呢?Phillip认为主要有三大原因。
第一个原因:Task Generality
当一个AI模型只需要完成一种特定任务(比如图像分类)时,实现的方法有很多种。
但如果需要这个AI模型同时胜任一系列不同的任务时,实现的方式就会少得多。
如下图所示,每个任务目标都会对模型施加额外的约束。当我们需要一个模型同时能够做翻译、做问答、写代码、解数学题的时候,它的表征空间会收敛到一个很小的范围。
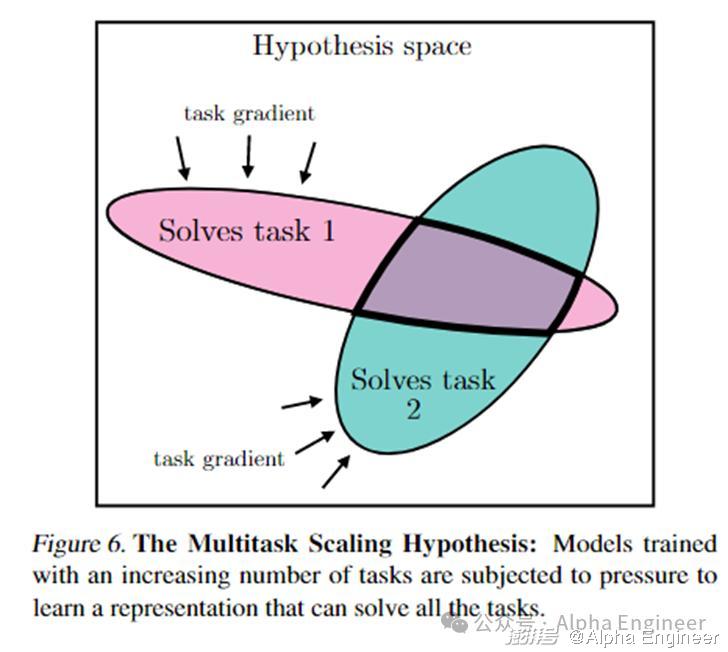
事实上,大语言模型可以看做是一个多任务目标训练的过程。根据上文预测下一个token看似简单,但实则是一个包罗万象的任务集合。
多任务目标的训练向模型施加了更多约束,从而导向更紧致、更高质量的解决方案空间。
这是LLM能够涌现出智能的一种有力解释。

第二个原因:Model Capacity
模型越大,便越容易逼近全局最优表征,从而推动表征收敛。
如下图所示,黄色区域和绿色区域是两个AI模型的表征空间,层层同心圆可以看做是模型loss的等高线,位于圆心处是loss最低的全局最优解。
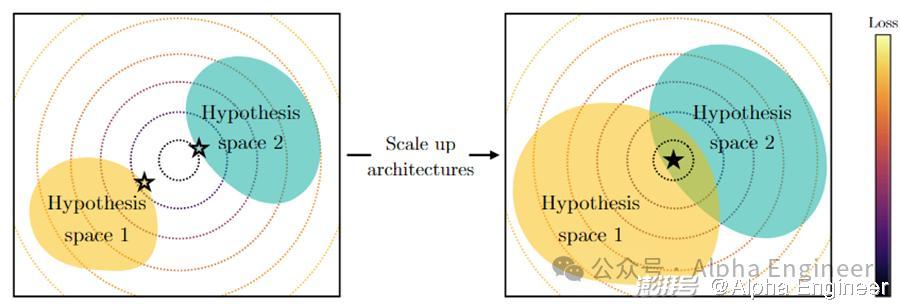
在左图中,由于两个模型的参数规模都比较小,沿着降低loss的方向进行梯度下降,只能求解出两个局部最优解,用☆表示。
随着模型参数规模的增加,黄色和绿色的色块范围在扩大,意味着两个AI模型的表征空间变大。在右图中两个模型能够找到一个共享的全局最优解(用★表示),实现表征收敛。
第三个原因:Simplicity Bias
深度神经网络天然遵循着奥卡姆剃刀原则,有着“简单性偏好”,倾向于选择所有可行解中的最简单的解决方案。
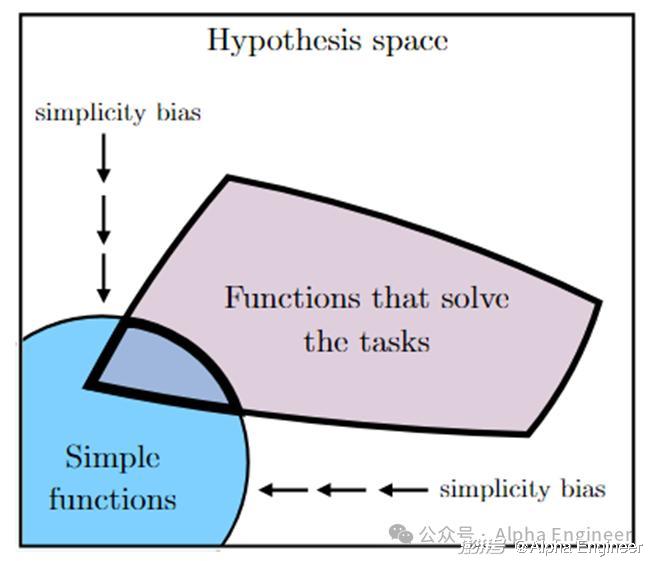
也许正是这种独特的性质,让深度神经网络模型从一众模型架构中脱颖而出,成为现代AI的奠基算法。

(6)Scaling有用,但未必高效
柏拉图表征假说有着几个重要推论,每个推论都对未来AI的发展有着方向性的指导意义。
根据柏拉图表征假说,随着模型参数、任务多样性、算力FLOP的增加,模型的表征会逐渐收敛趋同。
这是不是意味着只要Scaling up就可以实现AGI呢?
是也不是。虽然Scaling up能够实现表征收敛,但是不同方法的收敛效率可能天差地别。

举个例子,AlphaFold 3能够有效预测包括蛋白质在内的生物大分子结构,FSD能够通过图像识别实现无人驾驶。
蛋白质结构预测与无人驾驶可能是两类相对独立的任务。虽然说用一个统一的AI模型来同时实现AlphaFold 3和FSD的能力,应该能让模型的能力进一步增强,但训练过程可能会非常低效,性价比较低。

因此,对于某些独立任务而言,出于效率考量,可以单独训练一个shortcut模型,而不一定要依靠对于现实的统一表征。
在某些场景中,相比费尽力气取得全局最优解而言,高效地取得局部最优解更具备经济价值。

(7)重新理解多模态数据之间的关系
柏拉图表征假说让我们能够从一个新的视角审视多模态数据之间的关系。
假设你手上有M张图片和N段文字,为了训练出最强的CV模型,你不止应该训练全部M张图片,还应该把N段文字也纳入训练集中。
这其实已经成为AI业界的common practice,有不少优秀的CV模型都是从预训练大语言模型上微调而来的。
这个道理反之亦然。如果你想要训练出最强的文本模型,你不止该把全部N段文字拿来训练,还应该把M张图片也纳入训练集。
这是因为不同模态的数据背后,隐含着某种与模态无关的通用现实表征。
这意味着即使训练集中不存在跨模态配对数据(如文本-图片配对数据),纯粹的文本语料也对CV模型训练有直接帮助。跨模态配对数据的主要价值在于提升表征收敛的效率。

(8)结语:寻找表征世界的全局最优解
两千年前,柏拉图提出洞穴寓言,哲学家们开始运用逻辑工具、几何工具懵懂地探索现实的本质。
两千年后,人类的工具箱中多了一件超级武器,那就是AI。
“格物致知”的交接棒已经递给了AI科学家。
期待人类能够在这个时代,借助AI的力量寻找到表征世界的全局最优解,走出洞穴,探寻并理解高维现实,造福人类社会。
All of machine learning is footnotes to Plato.

作者:费斌杰 北京市青联委员 熵简科技CEO
欢迎关注我的公众号(Alpha Engineer),获取报告。
文章来源于互联网/AI生成
相关文章
